【代码】机器学习算法随机森林汇总
随机森林是一个较为常见的算法,在论文中也多有使用。我根据自己的经验,总结了如下的内容,供大家参考~
先简单介绍一下:随机森林(Random Forest)是一种集成学习(Ensemble Learning)方法,由Leo Breiman和Adele Cutler在2001年提出。它通过构建多个决策树(Decision Tree)来解决分类和回归问题,然后通过取平均值(回归问题)或取多数投票(分类问题)的方式来提高预测准确性、泛化能力和抗过拟合能力。
随机森林的基本思想是:构建多棵决策树,每棵树都是独立的,并且树中的特征是随机选择的,这样可以减小模型的方差。在进行预测时,随机森林对每棵树的预测结果进行平均(回归问题)或投票(分类问题),从而得到最终的预测结果。
理论基础
随机森林基于决策树构建而成。这里我详细聊聊随机森林的原理和整个的算法流程~
数学原理:
- 决策树:随机森林的基础是决策树。决策树是一种树结构,其中每个内部节点表示一个特征,每个叶节点表示一个类别(分类问题)或一个数值(回归问题)。
- Bagging(自助采样法):随机森林使用Bagging技术,即自助采样法。在训练每棵树时,从训练集中有放回地抽取一定数量的样本,用于构建决策树。
- 随机特征选择:对于每棵决策树的节点,在选择最优划分特征时,只考虑一个随机子集的特征。这样做的目的是增加树之间的多样性,减少过拟合。
- 集成预测:对于分类问题,随机森林通过投票机制(每棵树投票选择最终类别)来做出最终的分类决策;对于回归问题,通过取所有树的预测值的平均来得到最终的回归值。
算法流程:
- 随机采样:从训练集中有放回地抽取样本,构建每棵决策树的训练集。
- 随机特征选择:对于每棵决策树的每个节点,在一个随机的特征子集中选择最优的特征来进行节点划分。
- 构建决策树:根据选择的特征,递归地构建决策树,直到满足停止条件(如节点中样本数小于某个阈值,树的深度达到预设的最大深度等)。
- 集成预测:对于分类问题,通过投票机制确定最终类别;对于回归问题,取所有树的预测值的平均值作为最终预测值。
- 最终结果:对于分类问题,输出得到的最终类别;对于回归问题,输出平均预测值。
大家通过以上步骤,随机森林能够利用多棵决策树的集成学习能力,提高模型的准确性和泛化能力。
应用场景
随机森林适用于各种分类和回归问题,特别是对于复杂的、高维度的数据集,以及需要处理大量特征的问题。由于随机森林具有很好的泛化能力和抗过拟合能力,因此在许多实际问题中表现出色。
优点:
- 准确性高:随机森林能够通过组合多个决策树来提高预测准确性。
- 泛化能力强:随机森林对于未见过的数据具有很好的泛化能力。
- 抗过拟合:由于随机森林中每棵树都是在不同的样本和特征子集上训练的,因此具有很好的抗过拟合能力。
- 能够处理大规模数据集:随机森林的训练过程可以并行化,因此能够有效处理大规模数据集。
缺点:
- 模型解释性差:由于随机森林是一个集成模型,包含多个决策树,因此模型的解释性相对较差。
- 训练和预测速度较慢:相对于单棵决策树,随机森林需要构建多棵决策树,因此训练和预测速度可能较慢。
运用时的前提条件:
- 数据集质量:随机森林对于高质量的数据集效果更好,因此需要确保数据质量高,无缺失值、异常值等。
- 特征选择:虽然随机森林能够处理大量特征,但仍然需要进行特征选择以提高模型效果。
- 参数调优:随机森林有一些重要的参数需要调优,如树的数量、每棵树的最大深度等。
常见应用案例:
在金融领域,可以使用随机森林来预测客户是否会违约。通过收集客户的个人信息、信用历史等数据,构建随机森林模型来预测客户是否会违约,从而帮助银行进行风险管理。
随机森林适用于各种分类和回归问题,具有准确性高、泛化能力强、抗过拟合等优点,但模型解释性差、训练和预测速度较慢。在应用随机森林时,需要注意数据质量、特征选择和参数调优等问题。
这里,咱们举一个案例,整个案例包括数据预处理、模型训练、可视化和算法优化。
# 导入所需的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import make_classification
# 创建一个随机数据集
X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_classes=2, random_state=42)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建一个随机森林分类器
rf = RandomForestClassifier(random_state=42)
# 设置要调整的参数
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['auto', 'sqrt', 'log2']
}
# 使用GridSearchCV进行参数调优
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train)
# 获取最佳参数
best_params = grid_search.best_params_
# 使用最佳参数重新构建随机森林模型
best_rf = RandomForestClassifier(**best_params, random_state=42)
best_rf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = best_rf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
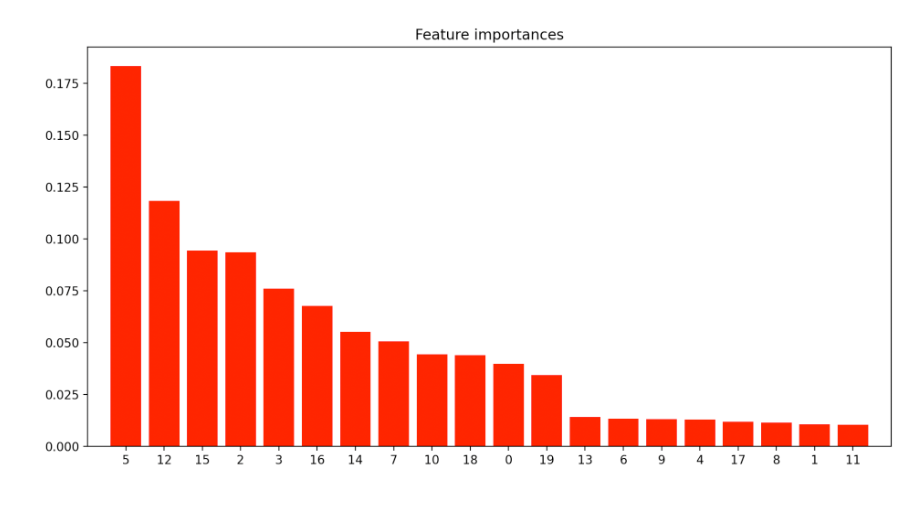
# 特征重要性可视化
feature_importances = best_rf.feature_importances_
indices = np.argsort(feature_importances)[::-1]
plt.figure(figsize=(12, 6))
plt.title("Feature importances")
plt.bar(range(X.shape[1]), feature_importances[indices],
color="r", align="center")
plt.xticks(range(X.shape[1]), indices)
plt.xlim([-1, X.shape[1]])
plt.show()整个代码说明的是,如何使用随机森林进行分类任务。首先创建一个随机数据集,然后将数据集划分为训练集和测试集。然后使用GridSearchCV来搜索最佳参数。
最后,使用最佳参数重新构建随机森林模型,并在测试集上进行预测。
特征重要性图表显示了每个特征对模型的贡献程度,可以帮助我们理解模型的工作原理。
这就是全部的内容了,如果有问题,欢迎大家在评论区留言~